File table is special type of table to store files and folder in SQL Server 2012 onwards, these files and folder are easily accessible through windows explorer it as good as windows file system. We can add, delete file to windows directory by copy and paste then it will shows those files in table FileTable
We can manage files from windows directory as well as using SQL server management studio i.e. delete/truncate/update/select etc.
File tables have specific set of columns while creation of filetable we no need to specify list of columns.
To create filetable database should have file stream file & file group
2. Every rows represent file or folder
3. We can perform DML operation on selected columns i.e. non computed columns
4. Every rows hold followings
(i) File stream column for stream data and file_id as GUID
(ii) Path and parent path locator as an hierarchy
(iii) Ten file attribute i.e. file creation/access/modification etc.
(iv) Type column which support full text and semantic search
5. We cannot change existing table to file table
6. We must need to specify parent directory(i.e. Dineshbabuverma) at database level
7. Must have valid file stream file and file group
8. We cannot create table level constraints while creation of table but we can add constraints after creation of table
9. We cannot create table filetable in database tempdb.
Let us perform steps to create table filetable consider following scenarios
Table Name : MyFileTable
Database Name : MyFileTableDB
Directory Name : Dineshbabuverma
File Group Name : FIleTableFG
FileTable File Name : FileTableFile
(i) Create Database with given filegroup and filename : MyFileTableDB
CREATE DATABASE [MyFileTableDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyFileTableDB', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\MyFileTableDB.mdf' , SIZE = 15360KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
FILEGROUP [FIleTableFG] CONTAINS FILESTREAM DEFAULT
( NAME = N'FIleTableFile', FILENAME = N'C:\FIleTableFile' , MAXSIZE = UNLIMITED)
LOG ON
( NAME = N'MyFileTableDB_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\MyFileTableDB_logFile.ldf' , SIZE = 38208KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
If we have existing database we can file group and file as type filestream using below commands
ALTER DATABASE MyFileTableDB
ADD FILEGROUP MyFileTableFG contains filestream;
GO
ALTER DATABASE MyFileTableDB
ADD FILE
( NAME = 'MyFileTableFile', FILENAME = 'C:\MyFileTableFile'
)
TO FILEGROUP MyFileTableFG;
GO
(ii) Enable Filestream
EXEC sp_configure filestream_access_level, 2
RECONFIGURE
GO
(iii) Set Filestream Details as below
ALTER DATABASE MyFileTableDB
SET FILESTREAM (NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'Dineshbabuverma')
Same we can set Using UI as per below screen, marked in color yellow
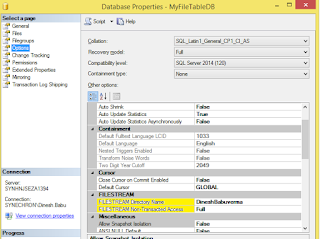
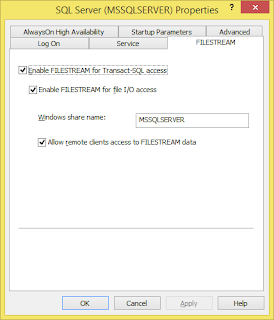
(iv) Enable Filestream for Transact SQL Access: first go to SQL Server configuration manager, Right click on SQL Server Instance Properties Filestream tab and enable filestream access as below
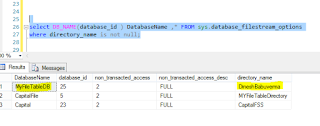
select DB_NAME(database_id ) DatabaseName ,* FROM sys.database_filestream_options
where directory_name is not null;
Output of query:
Now we can create file Table and explore the file table directory according to below figure.
CREATE TABLE MyFIleTable AS FILETABLE
output of the select command
select * FROM MyFIleTable

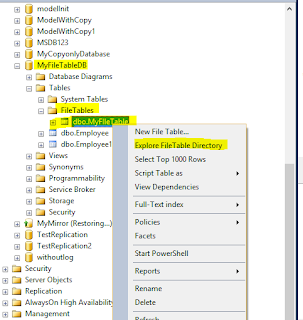
Once we click on explore filetable directory it open windows file directory DineshBabuverma of table Myfiletable
Now let us just copy and paste some files as below

Now execute again select statement, we can see our files in table MyFileTable
select * FROM MyFIleTable

/*Below delete command will delete file IMG_20150829_161804067.jpg from windows directory, first execute then check in filedirectory*/
DELETE FROM MyFIleTable
WHERE stream_id ='869D2F26-2A61-E511-BE9B-4487FCD82C05'
select * FROM MyFIleTable

Now if we check files in windowsfiledirectory DineshBabuverma, we will see only two files
We can insert file into FileTable using below command
INSERT INTO [dbo].MyFIleTable
([name],[file_stream])
SELECT
'DP1.png', * FROM OPENROWSET(BULK N'D:\DP1.png', SINGLE_BLOB) AS FileData
;

For inserted file we can see additional one row in above result set, marked in color yellow.
Note: Please try above scenarios in development/test environment.
We can manage files from windows directory as well as using SQL server management studio i.e. delete/truncate/update/select etc.
File tables have specific set of columns while creation of filetable we no need to specify list of columns.
To create filetable database should have file stream file & file group
File Tables provide following features
1. Provides hierarchy of files and folders2. Every rows represent file or folder
3. We can perform DML operation on selected columns i.e. non computed columns
4. Every rows hold followings
(i) File stream column for stream data and file_id as GUID
(ii) Path and parent path locator as an hierarchy
(iii) Ten file attribute i.e. file creation/access/modification etc.
(iv) Type column which support full text and semantic search
5. We cannot change existing table to file table
6. We must need to specify parent directory(i.e. Dineshbabuverma) at database level
7. Must have valid file stream file and file group
8. We cannot create table level constraints while creation of table but we can add constraints after creation of table
9. We cannot create table filetable in database tempdb.
Let us perform steps to create table filetable consider following scenarios
Table Name : MyFileTable
Database Name : MyFileTableDB
Directory Name : Dineshbabuverma
File Group Name : FIleTableFG
FileTable File Name : FileTableFile
(i) Create Database with given filegroup and filename : MyFileTableDB
CREATE DATABASE [MyFileTableDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyFileTableDB', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\MyFileTableDB.mdf' , SIZE = 15360KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
FILEGROUP [FIleTableFG] CONTAINS FILESTREAM DEFAULT
( NAME = N'FIleTableFile', FILENAME = N'C:\FIleTableFile' , MAXSIZE = UNLIMITED)
LOG ON
( NAME = N'MyFileTableDB_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\MyFileTableDB_logFile.ldf' , SIZE = 38208KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
If we have existing database we can file group and file as type filestream using below commands
ALTER DATABASE MyFileTableDB
ADD FILEGROUP MyFileTableFG contains filestream;
GO
ALTER DATABASE MyFileTableDB
ADD FILE
( NAME = 'MyFileTableFile', FILENAME = 'C:\MyFileTableFile'
)
TO FILEGROUP MyFileTableFG;
GO
(ii) Enable Filestream
EXEC sp_configure filestream_access_level, 2
RECONFIGURE
GO
(iii) Set Filestream Details as below
ALTER DATABASE MyFileTableDB
SET FILESTREAM (NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'Dineshbabuverma')
Same we can set Using UI as per below screen, marked in color yellow

(iv) Enable Filestream for Transact SQL Access: first go to SQL Server configuration manager, Right click on SQL Server Instance Properties Filestream tab and enable filestream access as below

select DB_NAME(database_id ) DatabaseName ,* FROM sys.database_filestream_options
where directory_name is not null;
Output of query:

Now we can create file Table and explore the file table directory according to below figure.
CREATE TABLE MyFIleTable AS FILETABLE
output of the select command
select * FROM MyFIleTable


Once we click on explore filetable directory it open windows file directory DineshBabuverma of table Myfiletable

Now let us just copy and paste some files as below

Now execute again select statement, we can see our files in table MyFileTable
select * FROM MyFIleTable

/*Below delete command will delete file IMG_20150829_161804067.jpg from windows directory, first execute then check in filedirectory*/
DELETE FROM MyFIleTable
WHERE stream_id ='869D2F26-2A61-E511-BE9B-4487FCD82C05'
select * FROM MyFIleTable

Now if we check files in windowsfiledirectory DineshBabuverma, we will see only two files
We can insert file into FileTable using below command
INSERT INTO [dbo].MyFIleTable
([name],[file_stream])
SELECT
'DP1.png', * FROM OPENROWSET(BULK N'D:\DP1.png', SINGLE_BLOB) AS FileData
;

For inserted file we can see additional one row in above result set, marked in color yellow.
Note: Please try above scenarios in development/test environment.




